A couple of weeks ago, on the 27th of November 2020, I successfully defended my PhD thesis (summa cum laude). It was a unique experience to have the chance to discuss my work with several scientists who have inspired my work: Konrad Kording, Graham Taylor, Jeff Bowers and my supervisor Peter König.
It’s difficult and sad times for the world. COVID-19 is causing a lot of suffering to many people and keeping most of us at home almost all day. In Spanish we often say the idiom “to make a virtue out of necessity” to highlight the creativity that arises in the face of adversity. I thought of it after a great day attending a quarantine-induced online workshop on computational neuroscience organised by Pau Vilimilis Aceituno. Great talks, great people, all from home!
Since last October I am part of the Max Planck School of Cognition as a 0-year student. The past two weeks I had the chance to attend the second Cognition Academy, where I met the new PhD students and the rest of mentors of the programme. Not only was it a fun event, but it was also full of fantastic talks and workshops!
Our pre-print “Global visual salience of competing stimuli” is out on PsyArXiv! We run an eye-tracking experiment showing natural images side by side and trained a machine learning model to predict to direction of the first fixation (left or right) given a pair of images. The coefficients learned for each image characterize the likelihood of each image to attract the first saccade, when shown next to another competing stimulus, which we called global visual salience.
Interestingly, the global visual salience is independent of the local salience maps of the images, that is, the saccadic choice was not driven by local salient properties, but rather by, in part, the semantic content of the images. For instance, we found that faces and images with people have a higher global salience than urban, indoor or natural scenes.
We also confirmed a relatively strong general preference for the left image, although with high variability across participants. Besides, we found no influence of other aspects such as the familiarity with one of the images or the task to determine which of the two images had been seen before.
Images used in the eye-tracking experiment, sorted by their global visual salience, from left to right, and top to bottom.
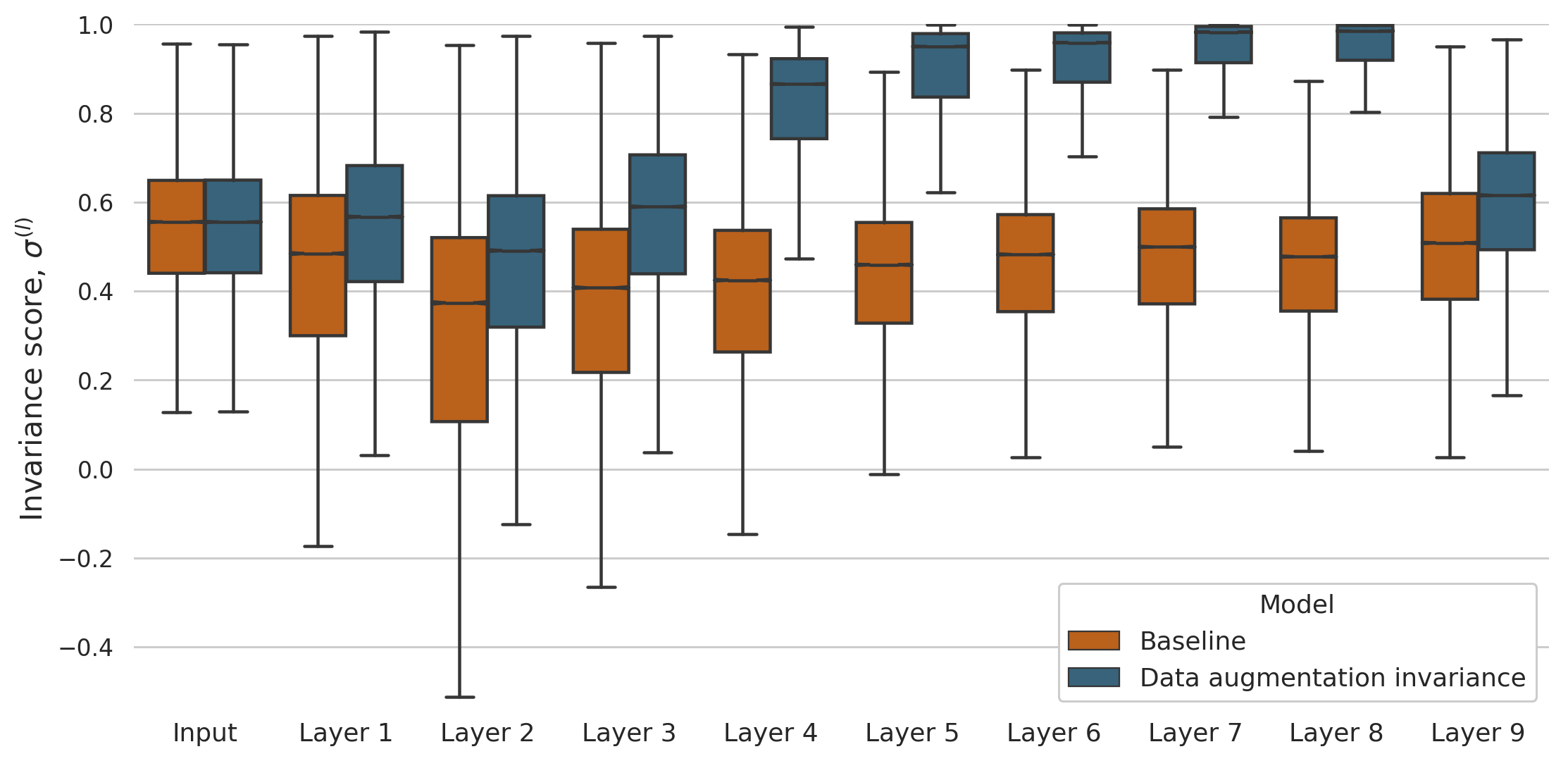
We have just uploaded to arXiv a new pre-print, “Learning robust visual representations using data augmentation invariance”. We first demonstrate that typical CNNs are remarkably sensitive to the common transformations of data augmentation. Second, taking inspiration from the invariance of the visual cortex to identity-preserving transformations, we add a loss term to the objective function that successfully learns more robust features.
This is still work in progress, initiated during my internship at the Cognition and Brain Sciences Unit of the University of Cambridge with Dr. Tim Kietzmann a few months ago, but we are excited about these promising results.
Given the remarkable discriminative power of deep neural networks to perform object categorization, one would expect that the features they learn are robust to simple transformations such as rotation, zoom, change of lightness, contrast, etc. However, the mean squared distance between the activations of an image and the activations of its transformations is actually larger than at the pixel space.
This contrasts with what has been often observed in the primate visual cortex: neurons across the hierarchy of the ventral visual stream are increasingly invariant to identity-preserving transformations. Taking inspiration from this, we implement a very simple, yet effective and efficient mechanism to promote the similarity between the representations that correspond to the same image. With our mechanism, data augmentation invariance, the models seem to easily learn more robust features, as shown in the figure below. Check the details in our paper!
Distribution of the invariance score at each layer of the baseline model and the model trained with data augmentation invariance
This week I am attending the VSS 2019 meeting and presenting a poster, “Saliency and the population receptive field model to identify images from brain activity”, the project I carried out during my internship at the Spinoza Centre for Neuroimaging in Amsterdam.
It is the first time I attend the annual meeting of the Vision Sciences Society (VSS) in St. Pete Beach, Florida (USA) and it is very exciting to participate in such a big event of the vision research community. Hard to keep track of the myriad of interesting talks and posters!
As always, it is also a great pleasure to see friends and colleagues from past conferences and meetings in the field.
The last workshop of the grant that funds my PhD, NextGenVis, took place last week in Pisa, Italy. I truly hope it’s only the formal end of the grant and our collaboration and friendship goes on.
A few days ago, on February 21st, it was the 3rd anniversary since I moved to Berlin to start my PhD. Time flies and it is incredible how many things happened to me in three years, both at the personal and the professional level. One of those things, one that makes me feel very privileged, is having been part of a fantastic network of visual neuroscientists and prestigious institutions, a Marie Sklodowska-Curie Innovative Training Network named NexGenVis (“Training the Next Generation of Visual Neuroscientists”).
Needless to say, when I joined the group I was nothing close to a visual neuroscientists, but rather an early stage researcher in the field of computer vision. I still remember my first workshop in York in 2016, where I attended talks by renowned visual neuroscientists that I did not know, with lots of slides with brain imaging figures that said absolutely nothing to me. I was faced with the decision of either ignoring all that to simply focus on my deep learning projects, passively attend the other five workshops that would come and dismiss the resources that were around me; or make an effort to learn about visual neuroscience and get something out of all this. I chose the latter and last week I was not only able to follow the presentations of my PhD fellows and other invited speakers in Pisa, but some of them were truly inspiring.
Not only has NextGenVis given me the opportunity to learn about visual neuroscience, but also it has been a very enriching personal experience and I have made good friends on the way. Just as an example, I have spent the weekend after the workshop with my friend Alessandro Grillini travelling around Tuscany and enjoying his and his parents’ hospitality. I would be very sad if the end of NextGenVis means the end of the personal network we have built. I hope that this is just the beginning of more mature future scientific collaborations and the continuation of valuable friendship.
It’s been my pleasure to give a talk at Radoslaw M. Cichy’s lab. about some of my work during my PhD, “On the advantages of data augmentation for deep learning and computational neuroscience”.
Since I started getting in touch with visual computational neuroscience, I have learnt a lot and got inspiration from some of Radek’s papers, so I am very happy to have had the chance to present my work at his lab, Neural Dynamics of Visual Cognition, at the Freie Universität Berlin, as well as to meet him in person and talk to some of the members of the lab. They do very cool stuff!
My internship at the Cognition and Brain Sciences Unit of the University of Cambridge is over and I am back in Berlin!
It’s been almost three months living in Cambridge and working at the CBU with Dr. Tim Kietzmann and the time has passed so quickly. Hopefully soon we will start writing a manuscript about the worked I did in Cambridge, which I will continue now from Berlin.
The project was not too different from what I have been doing in Berlin, as it’s a follow up of my main research on data augmentation, but living in Cambridge was indeed quite different than living in Berlin! One is a small British city, the other is a big European capital; one has a scatter of Gothic colleges, the other has an eclectic mix of buildings; one has a fantastic offer of cask ales in its many pubs, the other has a wonderful offer of Spätis in its streets. This could follow endlessly. Just as a metaphor of the difference, see the contrast of the photos I took on my last day in Cambridge and what I first encountered when I walked home from Ostbahnhof in Berlin.
King's college and one of the canals in CambridgeA kebab resturant outside Ostbahnhof and the Strasse der Pariser Kommune in Berlin