Data Augmentation Invariance
We have just uploaded to arXiv a new pre-print, “Learning robust visual representations using data augmentation invariance”. We first demonstrate that typical CNNs are remarkably sensitive to the common transformations of data augmentation. Second, taking inspiration from the invariance of the visual cortex to identity-preserving transformations, we add a loss term to the objective function that successfully learns more robust features.
This is still work in progress, initiated during my internship at the Cognition and Brain Sciences Unit of the University of Cambridge with Dr. Tim Kietzmann a few months ago, but we are excited about these promising results.
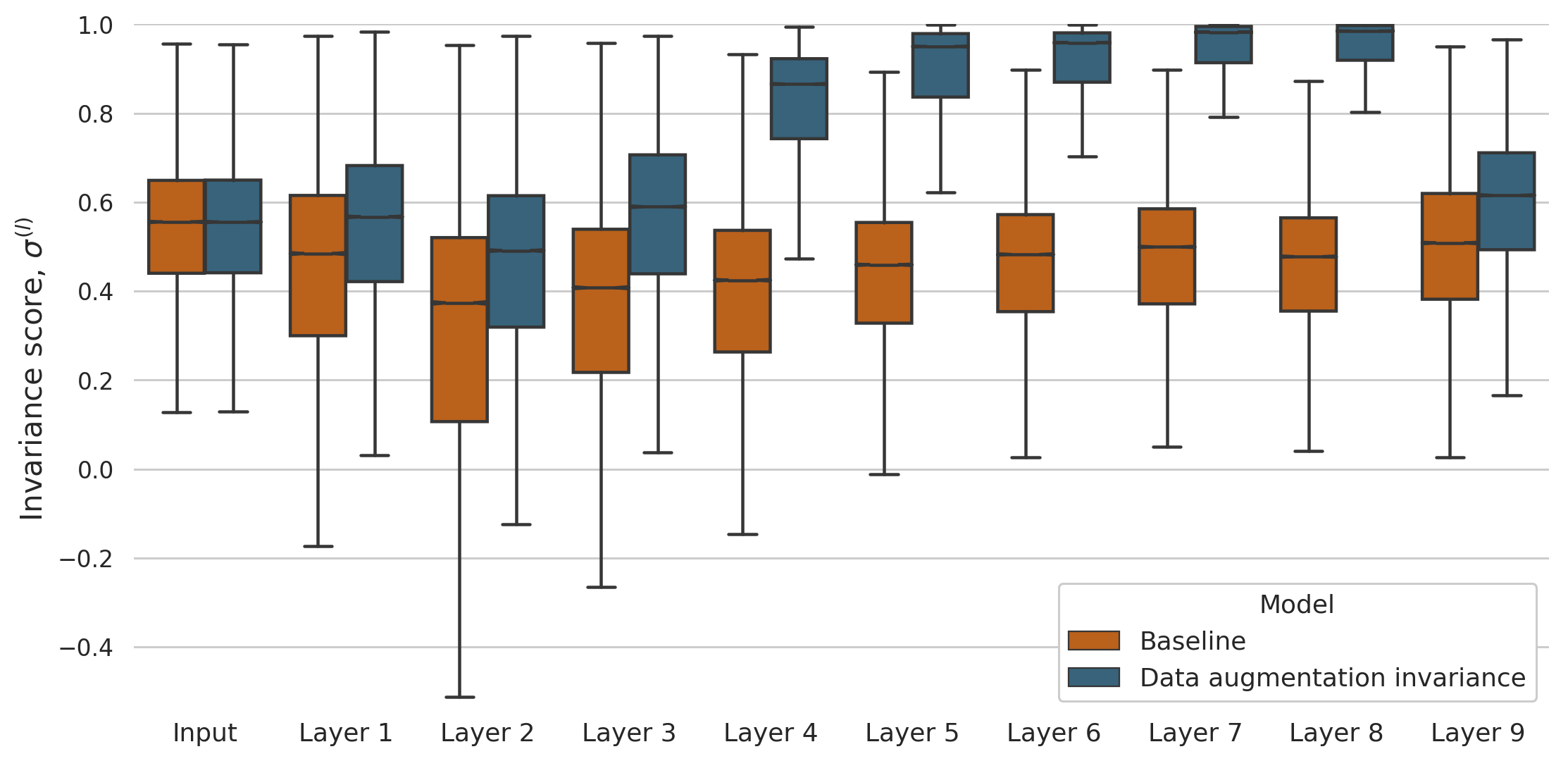
Given the remarkable discriminative power of deep neural networks to perform object categorization, one would expect that the features they learn are robust to simple transformations such as rotation, zoom, change of lightness, contrast, etc. However, the mean squared distance between the activations of an image and the activations of its transformations is actually larger than at the pixel space.
This contrasts with what has been often observed in the primate visual cortex: neurons across the hierarchy of the ventral visual stream are increasingly invariant to identity-preserving transformations. Taking inspiration from this, we implement a very simple, yet effective and efficient mechanism to promote the similarity between the representations that correspond to the same image. With our mechanism, data augmentation invariance, the models seem to easily learn more robust features, as shown in the figure below. Check the details in our paper!