Projects
Data augmentation instead of explicit regularization
This is the main project of my PhD. I came up with the idea after linking several observations: 1) Data augmentation seemed to provide much larger generalization gains than weight decay or dropout. 2) Weight decay and dropout are very sensitive to tuning their hyperparameters. 3) The deep learning literature lacked a systematic analysis of how these techniques interact with each other. The main conclusion is that weight decay and dropout seem unnecessary and they can be safely replaced by data augmentation.
Read more

Perceived emotion from images through deep neural networks
This is a yet unfinished project, whose aim is exploring the use of deep neural networks to predict the perceived emotion from natural images. Deep neural networks are extremely successful in a myriad of tasks, but the task of affective content analysis remains largely open, due to its subjective nature and the lack of large data sets that deep networks usually requires.
Read moreGlobal salience of competing stimuli
This is a side project of my PhD, where we explore some aspects of human visual perception of competing stimuli. In particular, we investigate, through eye-tracking experiments and a computational model, what makes a visual stimulus more effective in attracting visual attention when presented next to a competing stimulus. We denote this the global salience of a stimulus, in contrast to the local saliency of specific regions.
Read more
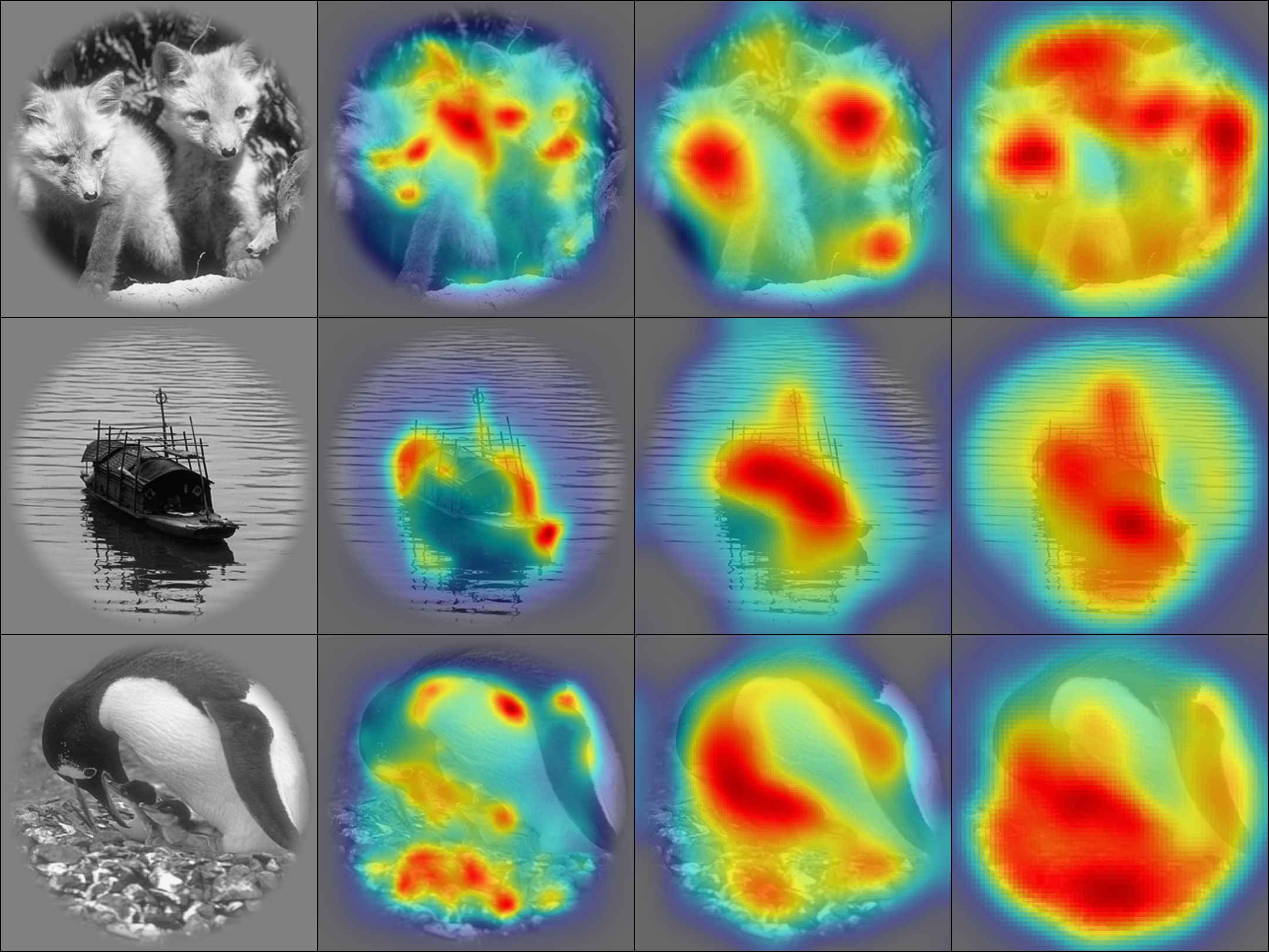
Image identification from brain activity
This was the project of my internship at the Spinoza Centre for Neuroimaging in Amsterdam in the Winter of 2018. I followed up on the paper by Zuiderbaan et al. 2017, in which they used the population receptive field model (pRF) and contrast information from the images to identify the stimulus seen by participants in an fMRI scanner. During my internship, I studied the effectiveness of saliency maps compared to contrast on multiple visual cortical areas. We found that saliency maps provide higher predictive power than contrast in V1, V2 and V3, suggesting that saliency may contain richer information that better explains the measured fMRI responses.
Read moreAesthetics and affective assessment of videos through visual descriptors
This is the project of my bachelor thesis. We explored the suitability of audiovisual descriptors for predicting subjective aspects of multimedia content, such as the aesthetic value or the elicited emotion and attention.
Read more